
概要
本記事ではchatGPTとスプレッドシートを使って、フリーテキスト情報(非構造化データ)からあらかじめ定めた構造化データに落とし込む方法について実務で使える形で細部まで含めて紹介いたします。
非構造化データとは何か?
非構造化データは、文章や画像、音声、動画など、特定の形式や規則に従っていないデータのことを指します。このタイプのデータは、従来のデータベースや表で扱いにくく、適切な処理が必要となります。
構造化データとは何か?
構造化データは、表やデータベースに格納された情報で、規則的な形式で整理されています。これにより、検索や分析が容易になり、仕事の効率化に役立ちます。
非構造化データから構造化データを得るメリット
非構造化データを構造化データに変換することで、情報の迅速な検索や分析が可能になります。これにより、業務の効率化が図られ、意思決定や戦略立案に有益な情報を得られるようになります。また、構造化データに変換することで、ビッグデータや機械学習の活用が容易になり、さらなるビジネスチャンスや競争力向上が期待できます。
chat GPTを使った非構造化データの構造化方法
事前準備
スプレッドシートでchat GPTを使えるようにするためには以下が必要です
- Open AIのAPIを利用できるようにする
- Google スプレッドシートにOpen AIのAPIを使える拡張機能「GPT for Sheets™ and Docs」を導入する
Open AIのAPIを利用できるようにする
こちらについては、他サイトなどでもよく説明されているので、本記事では詳細の説明を省略します。以下より、Open AI APIに登録して、最終的にAPI keyを取得してください。

「GPT for Sheets™ and Docs」を導入する
スプレッドシートのアドオンを取得より、「GPT for Sheets™ and Docs」をインストールしてください。初回拡張機能利用時に、Open AI のAPI keyの入力を求められるので、入力するとchatGPTに関係するGPTの関数を利用できるようになります。
非構造化データを構造化データにする流れ
今回は「服」のフリーテキストデータを非構造化データとして扱います。このデータをGPT関数で構造化データとして出力させ、最後にセルに当てはめる処理を入れます。
スプレッドシートで実践
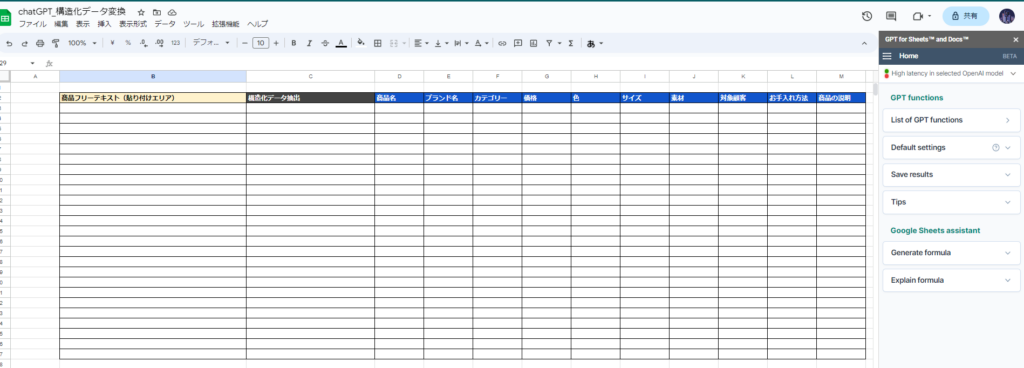
以下のようにセルを定義しました。商品フリーテキスト(貼り付けエリア)に非構造化の商品説明のテキストデータを貼り付けます。「構造化データ抽出」の列にGPT関数を使ってデータを構造化し、各商品の列に対応の項目を分解して反映させていきます。
| 商品フリーテキスト(貼り付けエリア) | 構造化データ抽出 | 商品名 | ブランド名 | カテゴリー | 価格 | 色 | サイズ | 素材 | 対象顧客 | お手入れ方法 | 商品の説明 |
商品説明テキストをchatGPTに生成してもらいました。以下が説明文です。実際このようなきれいな説明テキスト情報があるケースはないかもしれないですが、もっと乱雑なテキストのケースでも使えるかと思います。この文章を商品フリーテキストに貼り付けます。
洋服の説明文
"冬のアウターは、寒い季節に欠かせないアイテムです。弊社の冬のアウターは高品質で、デザイン性にも優れており、幅広い顧客層から支持されています。
「WINTER COAT」は、男女兼用であり、豊富なサイズ展開が特徴です。サイズはS、M、L、XL、XXLとなっており、多くの方にご利用いただけます。価格は、1万円台前半となっており、コストパフォーマンスに優れた商品となっています。
素材は、表地が撥水加工済みのポリエステル100%。裏地にはフリースを使用し、暖かさも兼ね備えています。さらに、フードは取り外し可能で、気温に合わせてアレンジが可能です。カラーバリエーションは、ベーシックなブラックとグレー、女性らしいピンクとライトブルーがあります。
対象顧客は、主に20代から40代の男女がメインとなります。学生や社会人の方々、特にアウトドア派の方にもご好評いただいています。
ブランド「WINTER STYLE」は、オリジナルブランドであり、他のブランドと比較しても高品質であり、多くのお客様から支持をいただいております。
また、当社の冬のアウターは、洗濯機で洗えるためお手入れも簡単です。冬の寒い季節にはぜひ「WINTER COAT」を着用して、快適な冬をお過ごしください。"では、「構造化データ」抽出に以下の数式を入れます。
=GPT("以下服の商品説明("&B9&")この商品について"&JOIN(":XX,", D8:M8)&":XX のフォーマットで出力""")急にイメージしづらくなりましたが、文字列を展開すると、以下のようになっています。
"以下()の中は服の商品説明です。
("冬のアウターは、寒い季節に欠かせないアイテムです。弊社の冬のアウターは高品質で、デザイン性にも優れており、幅広い顧客層から支持されています。
「WINTER COAT」は、男女兼用であり、豊富なサイズ展開が特徴です。サイズはS、M、L、XL、XXLとなっており、多くの方にご利用いただけます。価格は、1万円台前半となっており、コストパフォーマンスに優れた商品となっています。
素材は、表地が撥水加工済みのポリエステル100%。裏地にはフリースを使用し、暖かさも兼ね備えています。さらに、フードは取り外し可能で、気温に合わせてアレンジが可能です。カラーバリエーションは、ベーシックなブラックとグレー、女性らしいピンクとライトブルーがあります。
対象顧客は、主に20代から40代の男女がメインとなります。学生や社会人の方々、特にアウトドア派の方にもご好評いただいています。
ブランド「WINTER STYLE」は、オリジナルブランドであり、他のブランドと比較しても高品質であり、多くのお客様から支持をいただいております。
また、当社の冬のアウターは、洗濯機で洗えるためお手入れも簡単です。冬の寒い季節にはぜひ「WINTER COAT」を着用して、快適な冬をお過ごしください。")
この商品について商品名:XX,ブランド名:XX,カテゴリー:XX,価格:XX,色:XX,サイズ:XX,素材:XX,対象顧客:XX,お手入れ方法:XX,商品の説明:XX のフォーマットで出力"""フリーテキストの箇所を商品説明と記載しており、セルを参照しています。()を入れることでGPTが認識しやすくさせています。また、一番のポイントとなるところですが、この商品について商品名:XX,ブランド名:XX,カテゴリー:XX,価格:XX,色:XX,サイズ:XX,素材:XX,対象顧客:XX,お手入れ方法:XX,商品の説明:XX のフォーマットで出力”””と記述することで、構造化された(フォーマット化された)データとして出力してくれるようになります。
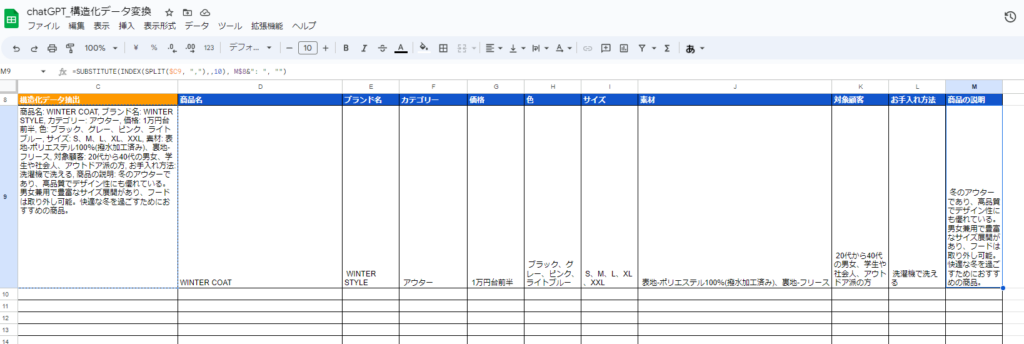
結果のセルを見てみます。
商品名: WINTER COAT, ブランド名: WINTER STYLE, カテゴリー: アウター, 価格: 1万円台前半, 色: ブラック、グレー、ピンク、ライトブルー, サイズ: S、M、L、XL、XXL, 素材: 表地-ポリエステル100%(撥水加工済み)、裏地-フリース, 対象顧客: 20代から40代の男女、学生や社会人、アウトドア派の方, お手入れ方法: 洗濯機で洗える, 商品の説明: 冬のアウターであり、高品質でデザイン性にも優れている。男女兼用で豊富なサイズ展開があり、フードは取り外し可能。快適な冬を過ごすためにおすすめの商品。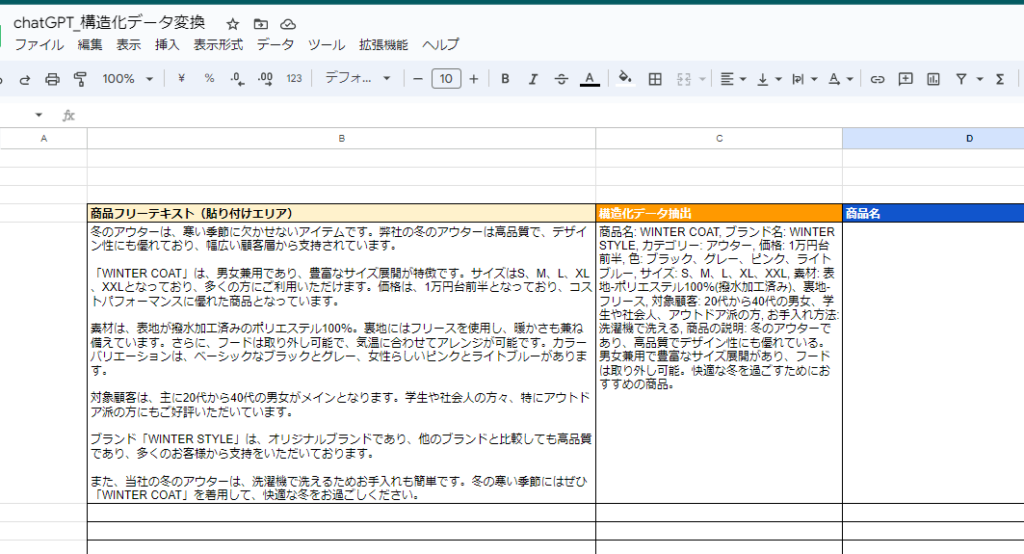
フリーテキストからうまく変換処理してくれました!
最後は、各構造化データのセルに当てはめられるように数式を入れておきます。
商品名の場合、以下の式を入れています。
=SUBSTITUTE(INDEX(SPLIT($C$9, ","),,1), D8&": ", "")SPLIT関数で、カンマ区切りのデータを配列に変換して、最初のインデックスである1を抽出します。すると商品名: 新商品の洋服というテキストが得られるので、最後に「商品名: 」という文字列をSUBSTITUTE関数で除去します。ブランド名やカテゴリーなどはINDEXを2,3…のようにずらしていき、かつ、除去する文字列も変更していけば良いです。
最終的に以下が得られました。フリーテキスト情報があれば、瞬時に構造化したデータを得られますね。
| 商品名 | ブランド名 | カテゴリー | 価格 | 色 | サイズ | 素材 | 対象顧客 | お手入れ方法 | 商品の説明 |
| WINTER COAT | WINTER STYLE | アウター | 1万円台前半 | ブラック、グレー、ピンク、ライトブルー | S、M、L、XL、XXL | 表地-ポリエステル100%(撥水加工済み)、裏地-フリース | 20代から40代の男女、学生や社会人、アウトドア派の方 | 洗濯機で洗える | 冬のアウターであり、高品質でデザイン性にも優れている。男女兼用で豊富なサイズ展開があり、フードは取り外し可能。快適な冬を過ごすためにおすすめの商品。 |
GPTに構造化データで出力させる理由
「商品名を抽出してください、ブランド名を抽出してください。」のように指示することで、各セルごとに、目的の情報を得ることもできますが、APIコールは少ない方がコスト・時間効率が良いので可能な限り関数を少なくする形で実現したいところです。今回は構造化データのフォーマットを指示することで実現しています。基本的にはこの方針でプログラムを組むと良いと思っております。
応用とまとめ
応用
AI(ChatGPT)とスプレッドシートを活用して、非構造化データであるフリーテキストを構造化データに整理する手法は、多岐にわたる応用が可能です。以下に5つの事例を紹介いたします。
- 顧客対応の最適化: 顧客からの問い合わせやクレーム情報を整理し、適切な対応策を短時間で見つけることができます。
- ソーシャルメディア分析: SNS上のコメントやツイートを構造化し、消費者のニーズや感情を把握し、マーケティング戦略の最適化に役立てることができます。
- 市場調査の効率化: ニュース記事や業界レポートを分析して、競合他社の動向や市場の変化を把握し、ビジネス戦略の策定に活用できます。
- 人事・採用プロセスの改善: 応募者の履歴書や職務経歴書を構造化し、適切な人材を効率的に選定できるようになります。
- 品質管理・製品改善: 顧客からの製品フィードバックや不具合報告を整理し、品質改善や製品開発の改善点を明確にすることができます。
AIとスプレッドシートを活用することで、非構造化データから有益な情報を得られるため、企業の競争力向上や効率化に大いに貢献できます。これらの事例は、様々な業界やビジネスに適用可能で、今後ますます重要性が増すことが予想されます。
まとめ
実際のデータは様々なフォーマットがあるので、今回紹介した服のデータのようにうまくいくケースは稀かもしれません。GPTへ指示する内容を対象のデータによって工夫する必要がありそうですね。このように自然言語を使って目的を達成するのは、話題のプロンプトエンジニアとしての仕事の一つなのでしょう。


コメント